[DataFrame을 합치기]
1) concat
2) merge
1) concat
- 단순히 하나의 DataFrame에 다른 DataFrame을 연속적으로 붙이는 방법
이 경우, 2개의 DataFrame의 인덱스와 컬럼이 서로 동일한 경우가 대부분
- 기본이 위,아래로 연결. axis 수정하여 좌우 연결 가능.
- outer 조인을 기본 방식으로 한다.
- key를 이용한 concat이 가능하다
- 데이터셋 생성
df1=DataFrame({
'A':['A0','A1','A2','A3'],
"B":['B0','B1','B2','B3'],
"C":['C0','C1','C2','C3'],
"D":['D0','D1','D2','D3']
})
df2=DataFrame({
'A':['A4','A5','A6','A7'],
"B":['B4','B5','B6','B7'],
"C":['C4','C5','C6','C7'],
"D":['D4','D5','D6','D7']
})
print(df1)
print('*'*60)
print(df2)
'''
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
**********************
A B C D
0 A4 B4 C4 D4
1 A5 B5 C5 D5
2 A6 B6 C6 D6
3 A7 B7 C7 D7
'''
- df1, df2를 상하로 병합
result=pd.concat([df1,df2],ignore_index=True)
#ignore_index : 각각의 데이터 프레임에서 부여받은 인덱스를 버리고,
# 병합된 데이터 프레임에서 새로 인덱스 설정
print(result)
'''
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
'''
- keys로 df1의 데이터를 ClassA, df2의 데이터를 ClassB라고 지정하여 각 데이터의 출처를 밝힘.
# keys 로 좌우 연결
result=pd.concat([df1,df2],keys=['ClassA','ClassB'])
result
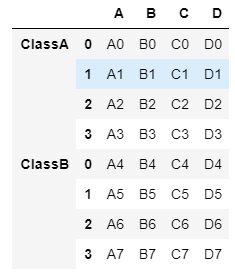
- 열의 개수가 달라도 병합 가능
# 4행 3열
df3=DataFrame({
'A':['A0','A1','A2','A3'],
"B":['B0','B1','B2','B3'],
"C":['C0','C1','C2','C3']
})
# 4행 4열
df4=DataFrame({
'A':['A4','A5','A6','A7'],
"B":['B4','B5','B6','B7'],
"C":['C4','C5','C6','C7'],
"D":['D4','D5','D6','D7']
})
df3
print("*"*50)
df4
'''
A B C
0 A0 B0 C0
1 A1 B1 C1
2 A2 B2 C2
3 A3 B3 C3
********************
A B C D
0 A4 B4 C4 D4
1 A5 B5 C5 D5
2 A6 B6 C6 D6
3 A7 B7 C7 D7
'''
- df3, df4 병합
# df3, df4 concat으로 병합 시, df3에는 D열이 없어서 NaN으로 채워진다.
result2=pd.concat([df3,df4],ignore_index=True)
print(result2)
'''
A B C D
0 A0 B0 C0 NaN
1 A1 B1 C1 NaN
2 A2 B2 C2 NaN
3 A3 B3 C3 NaN
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
'''
# NaN값은 'D'로 채우기
result2.fillna(value="D")
'''
A B C D
0 A0 B0 C0 D
1 A1 B1 C1 D
2 A2 B2 C2 D
3 A3 B3 C3 D
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
'''
- concat의 기본값이 outer조인 방식임을 알 수 있음
result3=pd.concat([df3,df4],join="outer")
print(result3)
'''
A B C D
0 A0 B0 C0 NaN
1 A1 B1 C1 NaN
2 A2 B2 C2 NaN
3 A3 B3 C3 NaN
0 A4 B4 C4 D4
1 A5 B5 C5 D5
2 A6 B6 C6 D6
3 A7 B7 C7 D7
'''
# inner join 방식으로 데이터 프레임을 연결하면 두 데이터에 모두 존재하는 컬럼값만 가져옴
result3=pd.concat([df3,df4],join="inner")
print(result3)
'''
A B C
0 A0 B0 C0
1 A1 B1 C1
2 A2 B2 C2
3 A3 B3 C3
0 A4 B4 C4
1 A5 B5 C5
2 A6 B6 C6
3 A7 B7 C7
'''
2) merge
- merge할 때 특정한 컬럼을 기준으로 병합한다.
- on을 사용하여 기준이 될 열을 설정.
- 데이터셋 설정
df1=DataFrame({
"Year":[2001,2002,2003,2004],
"Product_Code":[11,22,33,44],
"Price":[10000,20000,30000,40000]},
index=list("1234"))
df1
df2=DataFrame({
"Year":[2001,2002,2003,2004],
"Product_Code":[11,22,33,44],
"Price":[10000,20000,30000,40000]},
index=list("5678"))
df2
df3=DataFrame({
"Year":[2001,2012,2013,2004],
"Product_Code":[11,22,33,44],
"Color_num":[16,32,21,40]},
index=list("1234"))
df3

- df1, df2 merge
# df1과 df2 merge로 병합 시, index상관없이 좌우로 병합되고 중복된 값은 제거
result=pd.merge(df2,df3)
print(result)
'''
Year Product_Code Price Color_num
0 2001 11 10000 16
1 2004 44 40000 40
'''
- df1 데이터 수정
# df1 데이터 수정
df1_1=DataFrame({
"Year":[2001,2002,2003,2004],
"Product_Code":[11,22,33,44],
"Price":[11000,22000,33000,44000]},
index=list("1234"))
print(df1_1)
'''
Year Product_Code Price
1 2001 11 11000
2 2002 22 22000
3 2003 33 33000
4 2004 44 44000
'''
- on으로 병합 시 기준이 될 컬럼 설정
# df1과 df1_1 병합
# merge할 때 특정한 컬럼을 기준으로 병합한다...on을 사용하여 기준이 될 열을 설정
# on="year" >> year 외에는 데이터가 중복되더라도 다 표시된다.
# 2개의 컬럼으로 병합 가능 (year, Product_Code)
# 1개 컬럼을 기준으로 병합
result=pd.merge(df1,df1_1,on="Year")
print(result)
'''
Year Product_Code_x Price_x Product_Code_y Price_y
0 2001 11 10000 11 11000
1 2002 22 20000 22 22000
2 2003 33 30000 33 33000
3 2004 44 40000 44 44000
'''
# 2개 컬럼을 기준으로 병합
result2=pd.merge(df1,df1_1,on=["Year","Product_Code"])
print(result2)
'''
Year Product_Code Price_x Price_y
0 2001 11 10000 11000
1 2002 22 20000 22000
2 2003 33 30000 33000
3 2004 44 40000 44000
'''
- outer 조인 방식으로 merge
# outer는 기준이 되는 컬럼 Year의 데이터 중복과 상관없이 모두 출력
# how로 조인 기준 설정
# 결측치는 NaN으로 표기
result4=pd.merge(df1,df3,on="Year",how="outer")
print(result4)
'''
Year Product_Code_x Price Product_Code_y Color_num
0 2001 11.0 10000.0 11.0 16.0
1 2002 22.0 20000.0 NaN NaN
2 2003 33.0 30000.0 NaN NaN
3 2004 44.0 40000.0 44.0 40.0
4 2012 NaN NaN 22.0 32.0
5 2013 NaN NaN 33.0 21.0
'''
- inner 조인 방식으로 merge
result5=pd.merge(df1,df3,on="Year",how="inner")
print(result5)
'''
Year Product_Code_x Price Product_Code_y Color_num
0 2001 11 10000 11 16
1 2004 44 40000 44 40
'''
- left조인
result6=pd.merge(df1,df3,on="Year",how="left")
result6
'''
Year Product_Code_x Price Product_Code_y Color_num
0 2001 11 10000 11.0 16.0
1 2002 22 20000 NaN NaN
2 2003 33 30000 NaN NaN
3 2004 44 40000 44.0 40.0
'''
- right 조인
result7=pd.merge(df1,df3,on="Year",how="right")
result7
'''
Year Product_Code_x Price Product_Code_y Color_num
0 2001 11.0 10000.0 11 16
1 2004 44.0 40000.0 44 40
2 2012 NaN NaN 22 32
3 2013 NaN NaN 33 21
''''Data_Analysis > Numpy, Pandas' 카테고리의 다른 글
| [Pandas] DataFrame 함수 (where()) (0) | 2020.07.22 |
|---|---|
| [Pandas] 그룹연산(groupby, pivot_table) (0) | 2020.07.21 |
| [Pandas] 결측치 처리 (0) | 2020.07.21 |
| [Pandas] DataFrame 함수 (컬럼명 변경, 컬럼 추가/삭제/정렬) (0) | 2020.07.21 |
| [Pandas] DataFrame 함수 - 데이터 조회 (0) | 2020.07.21 |



댓글