들어가는 말
자주 사용하는 기본적인 기능을 정리한 글에 이어, 이번 글에서는 보다 심화된 내용으로 준비했습니다. 알고 있으면 편리하고 효율적으로 코드를 작성할 수 있는 기능 위주로 소개하고자 합니다.
[DATA STEP]
1. IF - OUTPUT
- IF ~ OUTPUT 은 DATA STEP에서 조건에 맞는 새로운 데이터 셋을 생성할 때 사용합니다.
- 데이터를 다룰 때 전체 데이터 셋에서 IF 또는 WHERE구문으로 특정 조건에 맞는 데이터만 추출하여 테이블을 생성하곤 합니다. 만약 조건이 다른 2개의 데이터 셋을 만든다면 각 조건을 반영한 DATA STEP을 2번 반복하여 만들 수도 있지만 IF ~ OUTPUT 으로 1개의 DATA STEP에서 2개의 새로운 데이터 셋을 만드는 것이 효율적입니다.
- 연체 여부에 따라 GOOD과 BAD 테이블을 생성하는 경우, 예시1은 각각 GOOD, BAD 추출 조건을 적용한 DATA STEP 2개를 만듭니다. 반면, 예시2는 IF ~ OUTPUT으로 1개 DATA STEP 에서 조건에 따라 GOOD과 BAD 데이터 셋을 생성합니다.
/* 예시1) 조건에 맞게 각각 데이터셋 만들기*/
DATA GOOD;
SET TEMP0;
IF 연체여부 <= 0;
RUN;
DATA BAD;
SET TEMP0;
IF 연체여부 > 0;
RUN;
/* 예시2) IF ~ OUTPUT으로 한번에 데이터셋 만들기 */
DATA GOOD BAD;
SET TEMP0;
IF 연체여부 <= 0 THEN OUTPUT GOOD;
ELSE OUTPUT BAD;
RUN;
2. RETAIN
RETAIN 은 DATA STEP 내에서 아래와 같이 2가지 기능을 합니다.
1) 변수 순서 고정
- DATA STEP에서 변수를 나열한 순서와 동일하게 테이블 내에서 변수 순서를 지정할 수 있습니다.
/* 테이블 내 변수 순서 : COL1 > COL2 > COL3 > COL4 */
DATA TEMP;
RETAIN COL1 COL2 COL3 COL4;
SET TEMP;
RUN;2) 컬럼내 행 연산
- RETAIN으로 한 컬럼 내에서 연산을 수행할 수 있습니다.
- 아래 예제는 ID별로 'O'나 'R' SIGN이 연속되는 횟수를 집계하는 문제입니다. 이 문제를 다음과 같이 풀 수 있습니다.
(1) SIGN의 값이 'O' 또는 'R'인지 확인하여 'O'나 'R'이 아니면 CNT에 0 값을 부여합니다.
(2) 만약 SIGN 값이 'O' 또는 'R'이라면 FIRST.ID로 해당 행의 ID 값이 이전 행의 ID값과 다른지 확인합니다. (이 작업을 수행하기 위해서는 미리 데이터 셋을 ID 기준으로 정렬해두어야 합니다.) SIGN 값이 'O' 또는 'R'이면서 새로운 ID 값이 시작되는 행이라면 CNT에 1을 할당합니다.
(3) 만약 SIGN 값이 'O' 또는 'R'이면서 현재 행의 ID 값이 이전 행의 ID와 동일하다면, 현재 행의 CNT 값은 이전 CNT 값 에 1을 더한 값으로 연산합니다.

/* 고객 ID 마다 O 또는 R SIGN이 연속되는 최대 횟수 구하기 */
DATA TEMP;
SET TEMP;
RETAIN CNT 0 ;
IF SIGN NOT IN('O', 'R') THEN CNT=0; /* SIGN이 O 또는 R이 아니면 CNT_R = 0 */
ELSE DO; /* SIGN이 O 또는 R인 경우, DO 다음의 명령문 실행 */
IF FIRST.ID THEN CNT=1; /* ID.FIRST(=첫번째 ID값) 이면, CNT_R =1 */
ELSE CNT=CNT+1; /* ID.FIRST가 아니면, 현재행 CNT_R = 이전행 CNT_R + 1 */
END;
RUN;** 중첩 IF문을 쓰거나, IF ~ THEN 구문에 따라 여러 개 변수를 처리하는 등 DO 명령어를 활용하여 여러가지 문장을 수행할 수 있습니다. 위의 예제에서는 SIGN 값이 'O'나 'R'을 만족하는 경우, DO ~ END 사이에서 ID 값에 따라 CNT를 연산하는 조건문을 수행합니다.
** FIRST : 위의 예시에서처럼 FIRST.ID라고 입력하면 ID열에서 ‘NICE1234’ 값이 시작되는 첫번째 지점인지 확인하는 것입니다. 1행은 FIRST.ID 결과가 TRUE가 됩니다. 그러나 2행은 1행과 동일한 값이 연속되는 지점이므로 FIRST.ID의 결과는 FALSE 입니다. 6번째 행은 5행의 값과 다른 ‘NICE5678’이 시작되는 지점이므로 FIRST.ID의 결과는 TRUE입니다.
[매크로(Macro)]
매크로 변수를 만드는 %LET과 CALL SYMPUT, 문장을 매크로화 하는 %MACRO 명령어를 다룹니다.
1. LET - 매크로 변수
- %LET 명령어를 통해 매크로 변수를 만들 수 있습니다. ‘%’를 붙여야 SAS는 이를 매크로 칼럼 생성으로 인식합니다.
- %LET으로 할당한 값은 문자 형식으로 저장합니다. 가령, %LET으로 2개의 변수에 각각 123, '123'이라는 값을 할당하며, 작은따옴표 때문에 두 변수의 값이 서로 다른 것으로 인식합니다.
%LET BASE_DATE = 201912;
%PUT &BASE_DATE.;
/* >> 201912 (문자형) */
%LET BASE_DATE = '201912';
%PUT &BASE_DATE.;
/* >> '201912' (문자형)*/- '%'로 시작하는 명령어는 SAS에 명령어를 인식시키거나 로그기록에만 출력을 할 때 사용하는 명령어입니다.
- '&'명령어를 통해 %LET 명령어로 생성된 매크로 변숫값을 불러올 수 있습니다. 모든 매크로는 ‘&’을 통해 불러옵니다.
2. CALL SYMPUT - 매크로 변수
- LET과 달리 변수의 값을 연동하여 출력할 수 있고, 함수를 적용한 값을 쓸 수도 있습니다.
- LET은 값을 직접 입력하는 반면, CALL SYMPUT은 함수로 값을 가공하거나 변수의 값을 끌어와 사용할 수 있습니다.
- CALL SYMPUT('매크로 변수명', '값') 또는 CALL SYMPUT('매크로 변수명', 변수) 형태로 사용합니다. 매크로 변수명은 반드시 ''로 감싸주어야 합니다.
- 다만 SYMPUT으로 생성한 매크로 변수는 매크로 변수를 생성한 DATA STEP과 동일한 DATA STEP 내에서 호출할 수 없습니다. 즉, 한 DATA STEP 내에서 SYMPUT으로 매크로 변수의 생성과 호출이 동시에 일어날 수 없으므로, 매크로 변수를 호출하기 전에 다른 DATA STEP에서 SYMPUT 매크로 변수를 만들어야 합니다.
/* CALL SYMPUT 사용*/
DATA _NULL_;
BASE_DATE = "201912";
CALL SYMPUT("FIRST_D", PUT(INTNX(INPUT(BASE_DATE||"01",YYMMDD8.),-1,'E'),YYMMDDN8.);
RUN;
%PUT &FIRST_D.; /*>> 20191130 */** DATA _NULL_ 이라고 입력하면 테이블이 생성되지 않습니다. SYMPUT 명령어는 %LET과 달리 단독으로 쓸 수 없어 DATA STEP 내에서 SYMPUT 명령어를 사용합니다. 그러나 굳이 매크로 변수 때문에 테이블을 생성할 필요는 없으므로 CALL SYMPUT 사용 시 테이블을 생성하지 않는 DATA _NULL_로 자주 이용합니다.
3. %MACRO - 문장 및 프로세스 매크로화
- %LET과 CALL SUMPUT은 특정 값을 변수에 할당하는 매크로였다면, %MACRO ~ %MEND는 DATA STEP, 프로시저 등 일련의 데이터 처리과정을 매크로로 만들 수 있습니다.
- 매크로화 하는 방법은 아래와 같습니다. %MACRO 매크로명(인자); 과 %MEND; 사이에 반복 및 자동화하고자 하는 명령문을 입력합니다. 그리고 %매크로명(인자); 로 매크로를 호출하여 매크로문 안의 명령문을 실행합니다.
%MACRO 매크로명(인자); /* 매크로 선언 */
/* 명령문, DATA STEP, 프로시저 등등 */
%MEND; /* 매크로 종료 */
%매크로명(인자); /* 매크로 호출 */- 아래 예시는 변수 값마다 우/불량 수를 집계한 테이블을 구하고, 각 변수별로 생성한 테이블을 하나로 결합하는 과정을 매크로화 한 것입니다. 변수별 우량/불량 건수 테이블을 만드는 과정이 반복되므로, 테이블을 생성하는 SQL 명령문을 매크로 안에 넣고, 변경되는 변수명만 인자로 전달합니다.
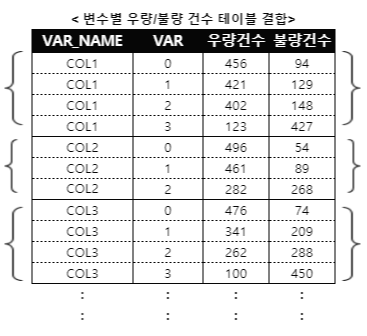
- 아래 로직에서 LOOP를 매크로명으로 호출하고 변수명을 &VAR. 로 전달하여 SQL 프로시저로 테이블을 생성합니다. 각 변수 별 테이블 생성과정이 끝나면 DATA STEP으로 각 테이블을 상하로 합쳐 하나의 테이블로 만듭니다.
/* 매크로 생성 */
%MACRO LOOP(VAR);
/*반복할 로직*/
PROC SQL ;
CREATE TABLE &VAR. AS
SELECT "&VAR." AS VAR_NAME
, &VAR. AS VAR
, SUM(CASE WHEN TARGET = 0 THEN 1 ELSE 0 END) AS 우량건수
, SUM(CASE WHEN TARGET = 1 THEN 1 ELSE 0 END) AS 불량건수
FROM CHG.VAR_TARGET_DEV
GROUP BY 1, 2
;QUIT ;
%MEND;
%LOOP(COL1);
%LOOP(COL2);
%LOOP(COL3);
%LOOP(COL4);
%LOOP(COL5);
%LET VAR_LIST = COL1 COL2 COL3 COL4 COL5 COL6;
DATA VAR_TOT ; SET &VAR_LIST. ; RUN; /* 테이블 합치기 */
PROC DELETE DATA = &VAR_LIST. ; RUN; /* 개별 테이블 지우기 */[반복문]
1. DO ~ TO
- DO ~ TO 반복문은 시작 시점, 종료 시점, 증감 간격을 설정하고 반복문 종료되는 지점에 END를 입력해주어야 합니다.
- 아래 예시 코드에서 DO ~ TO 반복문의 수행되는 순서는 다음과 같습니다.
(1) DO명령어 다음, I를 1부터 10까지 1 간격으로 반복하라는 문장을 입력합니다. 이에 따라 컬럼 I가 생성되고 값으로 1이 들어갑니다.
(2) 그런 다음, SUM_I 연산이 실행되어 SUM_I 컬럼의 값으로 2가 들어갑니다.
(3) 그리고 OUTPUT명령어에 의해서 이 값이 곧바로 출력이 되어 하나의 행을 구성합니다.
(4) DO의 반복을 끝내는 END 명령어를 만나면 DO I=1 과정이 끝납니다. 다시 위로 올라가서 DO I=2, 3,... 를 I가 10이 될 때까지 반복적으로 시행합니다. DO I=2일 때, SUM_I는 3이 될 것입니다.
DATA TEMP;
DO I=1 TO 10 BY 1; /* I의 값을 1부터 10까지 1씩 증가*/
SUM_I=I+1; /* I에 1을 더한 값을 SUM_I에 할당 */
END; /* DO 명령어를 종료 */
/*OUTPUT*/
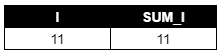
RUN;- 최종 결과는 아래 이미지와 같이 I =11, SUM_I =11로 구성된 1행 2열의 테이블을 산출합니다. 이 결과를 이해하기 위해서는 SAS에서 DO명령문을 처리하는 방식을 이해해야 합니다.
- 1행 2열의 결과가 나오는 이유는 DO 명령문 바깥에 OUTPUT이 존재하기 때문입니다. 위 코드에서 주석처리를 해두었지만, SAS는 OUTPUT 을 따로 입력하지 않아도 기본값으로 설정합니다. 반복문 밖에 OUTPUT이 존재하므로 I와 SUM_I의 값을 반복 처리한 후, 최종 결과 1개만 테이블에 입력됩니다.
- I가 11인 이유는 SAS가 DO 반복문을 실행하다가 I=11일 때, I가 10을 초과했음을 발견하고 정지하기 때문입니다. I = 11까지 진행하고 그다음 반복 작업을 멈추기 때문에 I의 값으로 11이 찍혀있습니다. SUM_I가 11인 이유도 같습니다. 반복문이 끝난 시점에서 SUM_I값은 I값이 업데이트되기 전 즉, I = 10일 때 연산된 값 11을 갖고 있습니다. 따라서 I = 11, SUM_I = 11 이 출력되는 것입니다.
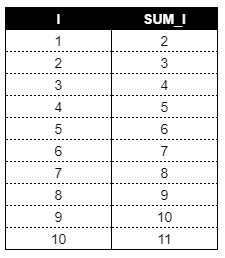
- OUTPUT의 명시한다면 그 위치에 따라 결과가 달라집니다. 아래 예시 코드에서는 OUTPUT을 SUM_I 연산 과정 다음에 입력했습니다.
(1) 반복문이 시작되면서 I = 1, SUM_I = 2가 됩니다.
(2) OUTPUT 명령어를 만나 테이블에는 I와 SUM_I 각각 1, 2가 입력됩니다.
(3) END 에서 DO I =1 반복문이 끝나고, 다시 DO 반복문을 I가 10이 될 때까지 시행합니다.
DO I=2일 때, SUM_I = 3 이고 이 결과는 테이블의 2번째 행에 기록됩니다.
DATA TEMP;
DO I=1 TO 10 BY 1; /*I의 값을 1부터 10까지 1씩 증가시키도록 합니다.*/
SUM_I=I+1; /*칼럼SUMMARY는 I의 값에서 10을 더한 값으로 합니다.*/
OUTPUT; /*결과값을 행에 추가합니다.*/
END; /*DO명령어를 종료합니다.*/
RUN;- SAS는 I = 11일 때 반복문을 멈추지만, OUTPUT이 반복문 안에 위치하기 때문에 반복문이 끝나기 전까지의 I, SUM_I 값만 테이블에 입력됩니다.
- 반복문에서 OUTPUT의 위치에 따라 결과가 달라질 수 있음을 유의해야 합니다.
2. DO UNTIL / WHILE
- DO UNTIL / DO WHILE 반복문은 조건을 입력하여 반복 종료 시점을 정합니다. DO ~ TO 반복문처럼 종료 시점의 값을 정확히 입력하기 어려울 때 용이합니다.
- DO UNTIL과 DO WHILE 모두 조건을 사용하여 반복문을 제어한다는 공통점이 있지만, DO UNTIL은 괄호 안에 반복이 종료되는 조건을 입력하고 DO WHILE문은 괄호 안에 반복이 지속되는 조건을 입력한다는 점에서 차이가 있습니다.
- 아래 예시로 살펴봅시다. SUM_I가 10 미만인 경우에 반복문을 수행하는 문제입니다.
(1) 초기값이 0인 SUM_I을 설정했습니다. (SUM_I 값을 따로 지정하지 않으면 결측 값이 되어 SUM_I+1의 결과는 언제나 결측값이 되어 UNTIL 조건을 만족하지 못하므로 무한 반복이 발생합니다. 따라서 예시에서는 SUM_I를 0으로 설정.)
(2) SUM_I 는 0으로 UNTIL 조건을 만족하지 않으므로 연산을 통해 SUM_I = 1이 됩니다.
(3) SUM_I 연산 결과는 OUTPUT 명령어를 만나 반복문이 끝나기 전 테이블에 기록됩니다.
(4) 첫 번째 반복 작업이 끝나고 다시 반복문을 수행합니다. 이때 SUM_I 값은 아직도 10보다 작으므로 반복문 내 연산 작업을 수행하게 되고, 그 결과도 테이블의 2번째 행에 기록됩니다.
/* DO UNTIL */
DATA TEMP;
SUM_I = 0;
DO UNTIL(SUM_I >= 10);
SUM_I=SUM_I+1;
OUTPUT;
END;
RUN;
/* DO WHILE */
DATA TEMP;
SUM_I = 0;
DO WHILE(SUM_I < 10);
SUM_I=SUM_I+1;
OUTPUT;
END;
RUN;
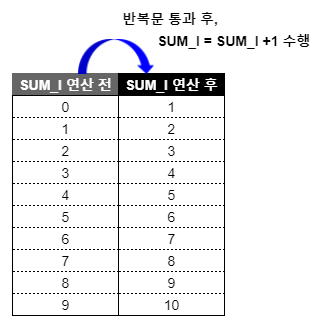
/*위의 2개 코드 결과는 같습니다. */- 아래 테이블 이미지에서 SUM_I 연산 후 컬럼의 마지막 행은 UNTIL 조건을 만족하는 SUM_I = 9까지의 결과입니다. 즉, OUTPUT을 반복문 내, SUM_I 연산 명령문 뒤에 입력했기 때문에 SUM_I =10인 시점에서 반복문은 종료되고 이전 반복 작업의 결과까지만 테이블에 남는 것입니다.
- 반복문은 매크로와 함께 사용하면 보다 효과적입니다. 아래 예시는 매크로 예시에서 사용한 코드에 반복문을 결합하여 자동화한 것입니다.
(1) 매크로 호출 시 변수명을 나열한 문자열을 매크로 변수 VAR_LIST로 만들어 LOOP 매크로의 인자로 전달합니다.
(2) LOOP 매크로는 인자로 전달받은 VAR_LIST에서 공백을 기준으로 I번째 변수명을 추출합니다. %DO %UNTIL 조건은 VAR_LIST에서 I번째 문자가 공백일 때까지 반복을 시행하는 것입니다. SCAN함수로 추출한 변수명을 VAR_NAME에 할당합니다.
(3) VAR_NAME에 할당된 변수명으로 SQL 프로시저를 실행합니다.
(4) EVAL함수로 매크로 변수인 I에 1을 더한 값을 새로운 I 값으로 할당합니다.
(5) 다시 반복문에서 I번째(=2,3,4..번째) 변수를 추출하여 SQL 프로시저를 실행하는 과정을 반복합니다.
(6) 반복문을 빠져나온 뒤, 변수 별로 생성된 테이블을 합쳐 하나의 새로운 테이블을 만듭니다.
- 반복문을 사용하지 않은 매크로 예시 코드와 비교했을 때, 매크로 안의 명령문이 길어졌습니다. 그러나 반복문을 활용한 매크로의 경우 변수의 수만큼 매크로를 반복적으로 호출하지 않아도 되고, 개별 데이터 생성부터 결합까지 1회 매크로 호출로 처리할 수 있습니다. 즉, 좀 더 많은 부분을 자동화했습니다.
- 반복적으로 처리해야 하는 과정이 길어질수록 반복문과 결합한 매크로의 필요성이 높아집니다. 가령, 복잡한 데이터 처리 과정을 30일 치 일별 데이터에 대해 적용하는 경우가 있습니다. 이때, 동일한 데이터 처리 과정을 30번 적기보다 날짜를 인자로 전달하고 날짜만 바꾸면 코드도 훨씬 짧아지고, 코드를 작성하면서 발생하는 오류의 확률도 줄어듭니다.
%MACRO LOOP(VAR_LIST);
%LET I=1;
/* 반복문 시작 */
%DO %UNTIL ( %SCAN ( &VAR_LIST. , &I. ) = %STR( ) );
%LET VAR_NAME = %SCAN ( &VAR_LIST. , &I. ) ;
/*반복 로직*/
PROC SQL ;
CREATE TABLE &VAR_NAME. AS
SELECT "&VAR_NAME." AS VAR_NAME
, &VAR_NAME. AS VAR
, SUM(CASE WHEN TARGET = 0 THEN 1 ELSE 0 END) AS 우량건수
, SUM(CASE WHEN TARGET = 1 THEN 1 ELSE 0 END) AS 불량건수
FROM CHG.VAR_TARGET_DEV
GROUP BY 1, 2
;QUIT ;
%LET I= %EVAL(&I.+1); /* EVAL() : 숫자형 연산 함수 */
%END;
DATA VAR_TOT ; SET &VAR_LIST. ;RUN; /* 개별 테이블 이어 붙이기 */
PROC DELETE DATA = &VAR_LIST. ;RUN; /* 개별 테이블 삭제 */
%MEND loop;
/* 매크로 호출 */
%LET VAR_LIST = col1 col2 col3 col4 col5 ;
%LOOP(&VAR_LIST.);** SCAN(문자열, N, 구분자) : 구분자를 기준으로 분리한 문자열에서 N번째 단어를 추출합니다. 구분자를 따로 지정하지 않으면 공백과 특수문자( . < ( + & ! $ * ) ; ^ - / , % |)를 기본값으로 문자열을 구분합니다.
** EVAL(산술/논리/비교 연산식) : 매크로 변수에 숫자를 입력해도 문자 타입으로 인식하기 때문에 매크로에서 숫자 연산을 위해 %EVAL() 을 주로 사용합니다. EVAL함수는 괄호 안에 있는 문자 타입의 정수를 정수 타입으로 변환하고 연산식의 결과도 정수타입으로 반환합니다. 다만, 괄호 안에 실수 타입의 숫자를 입력하거나 연산 결과가 실수 타입인 경우 %EVAL로 처리가 어려워 %SYSEVALF()를 사용하기도 합니다.
3. 마무리
본편에서는 매크로, 반복문, RETAIN 등 복잡한 데이터 처리를 효율적으로 할 수 있는 방법 위주로 다루었습니다. 추가적으로 작성 요청할 부분이 있거나, 수정 사항이 있다면 피드백 부탁드립니다. 의견을 적극 반영하여 완성도를 높여가겠습니다.
'Data_Analysis > SAS' 카테고리의 다른 글
| [SAS] 자주 쓰는 기능 정리 (2) | 2021.09.08 |
|---|---|
| [SAS] RETAIN (0) | 2021.04.19 |
| [SAS] 반복문 활용 (1) | 2021.02.27 |
| [SAS] PROC FREQ (1) | 2021.02.09 |
| [SAS] PROC TABULATE (0) | 2021.01.28 |



댓글