[그룹화]
- 데이터 그룹 기반의 집계는 단일 컬럼의 데이터를 그룹화하고,
해당 그룹의 다른 여러 컬럼을 사용해서 계산하기 위해 카테고리형 데이터를 사용합니다.
- 그룹화 작업은 아래와 같은 단계로 이뤄집니다.
(1) 하나 이상의 컬럼을 그룹화 (Relational Grouped Dataset 반환)
(2) 집계 연산을 수행 (DataFrame 반환)
- 그룹화 코드
(1) 기본적인 그룹화
// 그룹화
retail_all.groupBy("InvoiceNo","CustomerId").count().show()
(2) 표현식을 활용한 그룹화
retail_all.groupBy("InvoiceNo").agg( //agg 메서드로 여러 집계 처리를 한 번에 지정
count("Quantity").alias("quant"), //트랜스포메이션이 완료된 컬럼에 alias메서드를 적용
expr("count(Quantity)") //표현식을 사용하여 집계
).show()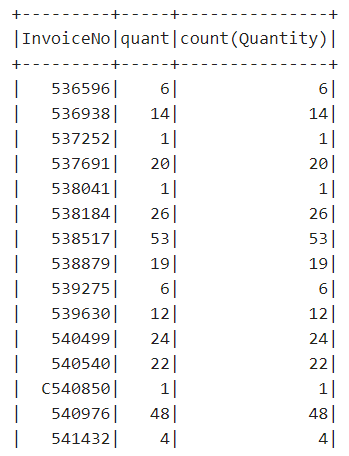
(3) 맵을 이용한 그룹화
: 컬럼을 키로, 수행할 집계 함수의 문자열을 값으로 하는 맵 타입을 사용하여 트랜스포메이션을 정의합니다.
수행할 집계 함수를 한 줄로 작성하면 여러 컬럼명을 재사용할 수 있습니다.
import org.apache.spark.sql.functions.{avg,stddev_pop}
retail_all.groupBy("InvoiceNo").agg("Quantity"->"avg","Quantity"->"stddev_pop").show()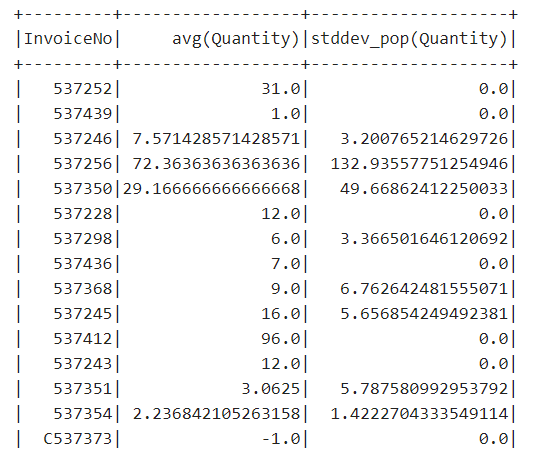
'Data_Analysis > Spark, Zeppelin' 카테고리의 다른 글
| [Spark] Window 함수 (0) | 2021.03.11 |
|---|---|
| [Spark] 집계 연산 (0) | 2021.03.07 |
| [Spark] 구조적 API 기본 연산2 - 로우 (0) | 2020.12.26 |
| [Spark] 구조적 API 기본 연산1 - 컬럼 (0) | 2020.12.26 |
| [Spark] 구조적 API 개요 (0) | 2020.12.23 |




댓글