Spark 포스트는 책 「스파크 완벽 가이드 : 스파크를 활용한 빅데이터 처리와 분석의 모든 것」를 바탕으로 쓴 것임을 알려드립니다.
또한, Scala 코드 위주로 작성한 점 참고 바랍니다.
스파크 완벽 가이드
스파크 창시자가 알려주는 스파크 활용과 배포, 유지 보수의 모든 것. 오픈소스 클러스터 컴퓨팅 프레임워크인 스파크의 창시자가 쓴 스파크에 대한 종합 안내서다. 스파크 사용법부터 배포, 유
www.aladin.co.kr
1. 구조적 API 종류
구조적 API에는 다음과 같은 분산 컬렉션 API가 있습니다.
- Dataset
- DataFrame
- SQL 테이블과 뷰
2. DataFrame과 DataSet
1) DataFrame과 DataSet 모두 로우와 컬럼을 가지는 분산 테이블 형태의 컬렉션.
2) 스파크의 DataFrame은 Row타입으로 구성된 DataSet
3) DataFrame과 DataSet 비교
| DataFrame | DataSet |
| 비(非)타입형 | 타입형 |
| 스키마에 명시된 데이터 타입의 일치여부를 런타임 시점에 확인 |
스키마에 명시된 데이터 타입의 일치여부를 컴파일 시점에 확인 |
| Scala, Java, Python, R에서도 가능 | JVM 기반 언어인 Scala와 Java에서만 지원 |
4) DataFrame의 경우 스키마로 컬럼명과 데이터 타입을 정의.
- 스키마는 여러 개의 StructField 타입 필드로 구성된 StructType 객체.
- StructField는 이름,데이터 타입, null허용 여부(boolean) 지정.
- 컬럼과 관련된 메타 데이터 지정할도 가능.
// json파일 불러오고, Schema 확인
spark.read.format("json").load("json 파일의 저장 경로").schema
//스키마 생성
import org.apache.spark.sql.types.{StructField,StructType,StringType,LongType}
import org.apache.spark.sql.types.Metadata
val myManualSchema=StructType(Array(
StructField("DEST_COUNTRY_NAME",StringType,true),
StructField("ORIGIN_COUNTRY_NAME",StringType,true),
StructField("count",LongType,false,Meatdata.fromJson("{\"hello\":\"world\"}"))
))
3. 구조적 API 실행 과정
1) DataFrame/DataSet/SQL을 이용해 코드 작성
2) 정상적인 코드는 스파크가 논리적 실행 계획으로 변환
- 추상적인 트랜스포메이션만 표현(드라이버나 익스큐터 정보를 고려 X)
- 사용자의 다양한 표현식을 최적화된 버전으로 변환.
- 이때, 입력한 코드는 검증 전 논리적 실행 계획으로 변환.
- 테이블과 컬럼에 대한 검증 결과는 카탈리스트 옵티마이저로 전달
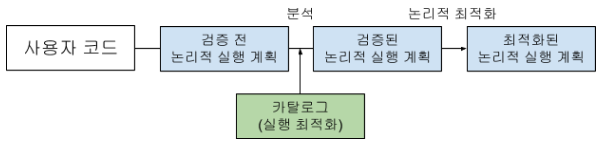
3) 논리적 실행 계획을 물리적 실행 계획으로 변환하며 그 과정에서 추가적인 최적화 방안을 탐색
- 논리적 실행 계획을 클러스터 환경에서 실행하는 방법 정의
- 비용 모델(조인 연산 비용 등)로 비교 후 최적의 전략 선택
- 물리적 실행 계획을 RDD와 트랜스포메이션으로 변환 & 코드를 RDD와 트랜스포메이션으로 컴파일
4) 클러스터에서 물리적 실행 계획(RDD 처리)을 실행
** 카탈리스트 엔진
: 실행 계획 수립과 처리에 사용하는 자체 타입 정보를 가지고 있어, 다양한 실행 최적화 기능을 제공합니다.
스파크가 지원하는 언어를 이용해 작성된 표현식을 카탈리스트 엔진에서 스파크의 데이터 타입으로 변환하여 명령을 처리하기 때문에 스칼라나 파이썬이 아닌 스파크에서 연산 수행도 가능합니다.
'Data_Analysis > Spark, Zeppelin' 카테고리의 다른 글
| [Spark] 구조적 API 기본 연산2 - 로우 (0) | 2020.12.26 |
|---|---|
| [Spark] 구조적 API 기본 연산1 - 컬럼 (0) | 2020.12.26 |
| [Spark] 아파치 스파크 들어가기 (0) | 2020.12.23 |
| [Zeppelin] Zepplelin 설치 및 실행 (0) | 2020.12.20 |
| [Spark] Window 10에 Spark설치 (0) | 2020.12.18 |




댓글