[랜덤포레스트]
- 여러개의 의사결정트리를 사용하여 값을 예측하는 앙상블 학습 방법의 일종이며, bagging알고리즘을 .
- 각각의 트리가 랜덤하게 Feature를 뽑아서 각각의 예측(prediction)을 다수결 또는 평균으로 최종 결론을 도출.
- 1개의 의사결정나무로 도출한 결론보다 우수한 성능을 보이며,단일 의사결정나무의 단점인 과적합(overfitting)극복.
[Bagging(Bootstrap Aggregation Sampling)]
중복을 허용하며 랜덤하게 표본을 추출하는 기법인 부트스트랩 (bootstrap) 과 결합을 의미하는 aggregating의 약자로,
조금씩 다른 표본 데이터로 여러 의사결정나무를 학습시키고 각 트리의 결과를 결합하는 방법이다.
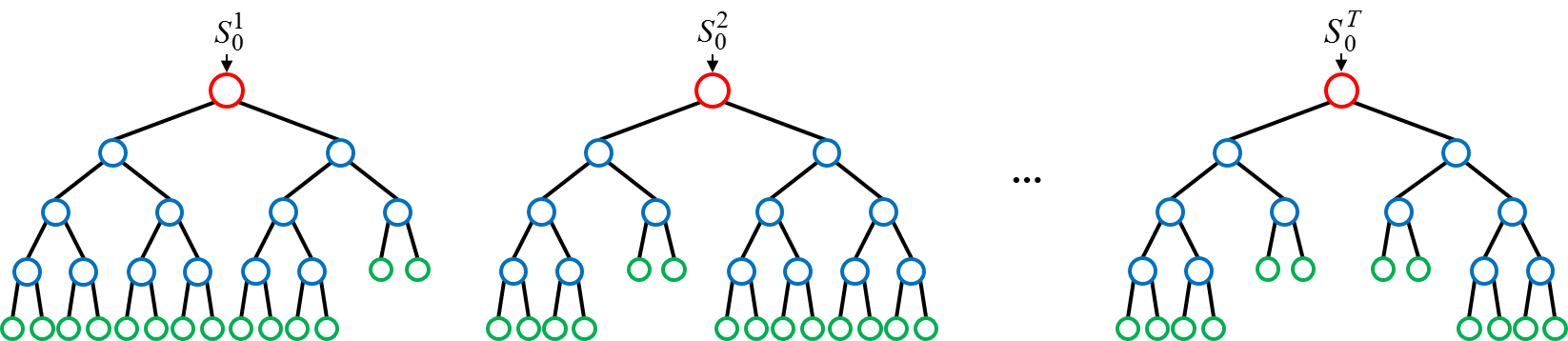
출처 : 위키피디아
https://ko.wikipedia.org/wiki/%EB%9E%9C%EB%8D%A4_%ED%8F%AC%EB%A0%88%EC%8A%A4%ED%8A%B8
[코드]
import sklearn as sk
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import datasets
from sklearn.model_selection import train_test_split
# iris 데이터
iris=datasets.load_iris()
iris
학습데이터(X_train, y_train)와 테스트데이터(X_test, y_test) 분리
# train과 test 분리
X_train,X_test,y_train,y_test=train_test_split(iris.data,iris.target,random_state=42,stratify=iris.target)
n_estimators : 랜덤포레스트 안의 결정 트리의 개수
- 대체로 n_estimators 가 클수록(=결정트리가 많을수록) 더 깔끔한 Decision Boundary 생성.
- 반면, 메모리 사용량과 학습 시간이 증가
random_state : 다음번에 학습을 할 때도 동일한 난수가 출력되도록 지정. random_state=뒤에 오는 숫자는 무작위로 선택하면 된다.
fit(X,y) : fit함수 안에 있는 train 데이터로 모델 학습
from sklearn.ensemble import RandomForestClassifier
# 모델 생성
rf=RandomForestClassifier(n_estimators=50,random_state=42)
# 학습
rf.fit(X_train,y_train)
predict(X_testset) : predict() 함수로 예측값 산출.
# 예측치 도출(pred)
pred=rf.predict(X_test)
# Accuracy_score
from sklearn.metrics import accuracy_score
accuracy= accuracy_score(y_test,pred)
accuracy
'Data_Analysis > MachineLearning' 카테고리의 다른 글
| [Machine Learning] Kernel SVM(Support Vector Machine) (0) | 2020.12.28 |
|---|---|
| [Machine Learning] SVM(Support Vector Machine) (0) | 2020.12.28 |
| [Machine Learning] NLP - 텍스트처리(Tokenize) (0) | 2020.10.31 |
| [MachineLearning] Decision Tree(의사결정트리) (1) | 2020.07.23 |



댓글