인터넷을 찾아보면 가상 환경에 Spark 설치한 예시는 많은데 로컬에 설치한 예시는 많지 않아서 포스팅해봅니다.
Spark설치를 위해서 python, java, scala, Winunit 등을 함께 설치해야 합니다.
또한, 하둡 없이 설치했습니다.
1. 프로그램 설치
1) Java, Python, Scala
- 저는 Python과 Java가 미리 설치되어 있었습니다. java와 Python은 아래 경로로 접속하여 다운로드할 수 있습니다.
자세한 내용은 이미 다른 블로그에 잘 정리되어있어 생략합니다.
- 다만 python 2 버전은 spark 지원하지 않는다고 하니, python은 버전 3 이상으로 받는 것이 좋습니다.
- Spark의 메인 언어인 scala도 함께 설치합니다. 저는 Scala2.11버전으로 설치했습니다.
https://www.oracle.com/java/technologies/javase-downloads.html
https://www.python.org/downloads/
Download Python
The official home of the Python Programming Language
www.python.org
https://www.scala-lang.org/download/2.11.12.html
Scala 2.11.12
Then, install Scala: ...either by installing an IDE such as IntelliJ, or sbt, Scala's build tool.
www.scala-lang.org
2) Spark
https://spark.apache.org/downloads.html
Downloads | Apache Spark
Download Apache Spark™ Choose a Spark release: Choose a package type: Download Spark: Verify this release using the and project release KEYS. Note that, Spark 2.x is pre-built with Scala 2.11 except version 2.4.2, which is pre-built with Scala 2.12. Spar
spark.apache.org
- 원래는 spark 3.0으로 설치했다가 spark 3.0은 scala2.12 버전을 써서 scala2.11버전을 쓰는 제플린과 버전 호환이 안 되는 경우가 있다고 하여 spark2.4.7버전으로 재설치했습니다.

-하이라이트 친 부분을 클릭하면 아래 화면으로 넘어갑니다. 상단에 있는 링크를 클릭하여 다운로드합니다.
- 다운로드하면 압축 파일을 풀어 적절한 경로에 둡니다.
3) Winutils 설치
Spark 다운로드할 때 선택한 하둡 버전에 맞춰 winutils.exe 파일을 다운로드합니다.
깃허브 : https://github.com/cdarlint/winutils
cdarlint/winutils
winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows - cdarlint/winutils
github.com
- 저는 하둡 2.7.7 버전의 폴더에서 받았습니다. 다른 파일은 필요 없고, winutils.exe 파일만 내려받으면 됩니다.
- Hadoop> bin 폴더를 생성하여 bin 폴더 안에 winutils.exe 파일을 저장합니다.


2. 환경변수 설정
1) Java, Python
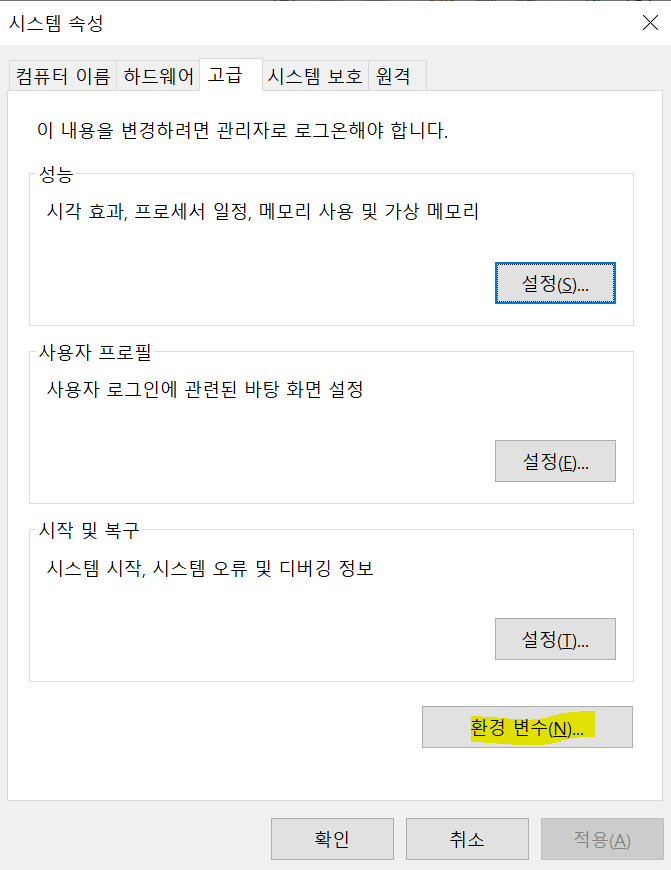
- 시스템 변수 편집에서 아래와 같이 경로를 설정해줍니다. 파일이 저장된 경로를 변수 값에 넣습니다.
- 변수이름 : JAVA_HOME
- 변수 값 : C:\Progra~1\Java\jdk1.8.0_201
** 원래 경로는 "C:\Program Files\Java\jdk1.8.0_201" 이지만 경로의 공백이 오류를 일으킬 수 있다고 하여 아래와 같이 편집했습니다.
** C:\Program Files는 C:\Progra~1, C:\Program Files (x86)는 C:\Progra~2 로 대체 가능합니다.
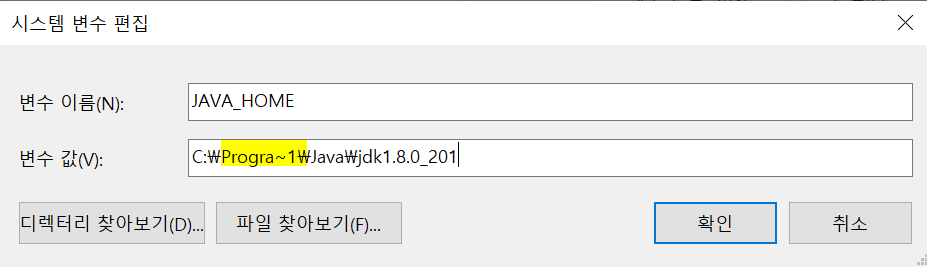
2) spark
- Spark도 아래와 같이 시스템 변수를 생성합니다.
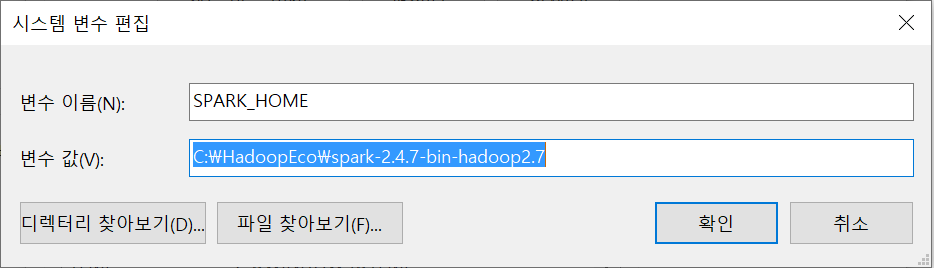
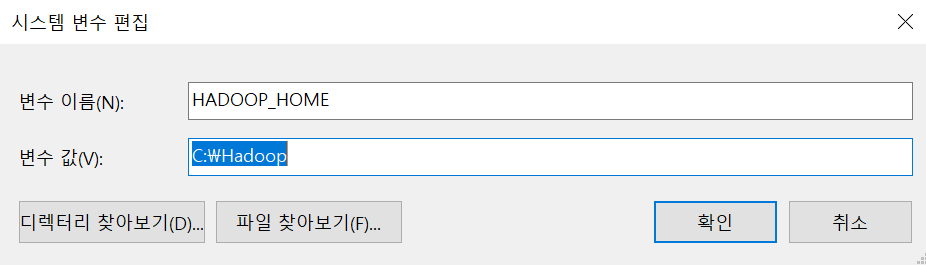
- Hadoop도 동일하게 만들어 줍니다.
- 시스템 변수 中 Path > %SPARK_HOME%\bin, %HADOOP_HOME%\bin 을 만듭니다.
- Scala,Java, Python도 동일한 방식으로 시스템 변수를 만들고, Path에 설정해 줍니다.
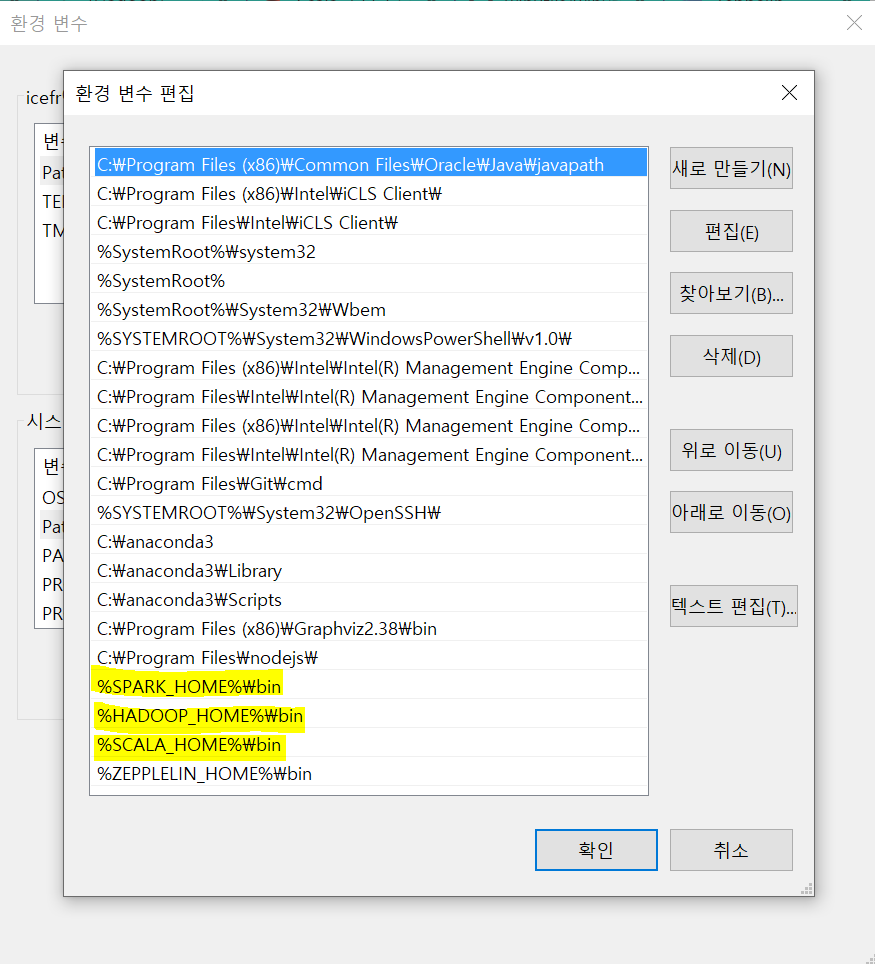
3. Spark 실행
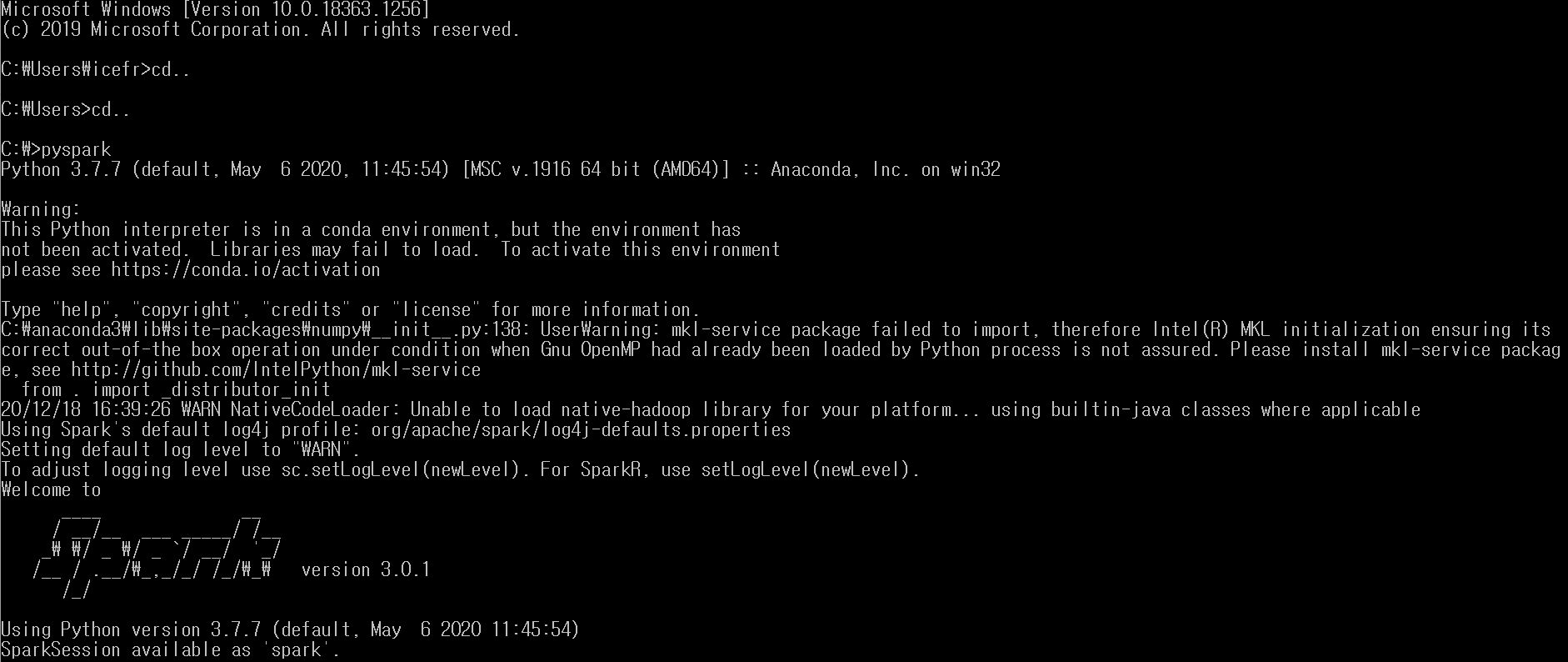
- cmd창을 열러 'pyspark'라고 입력하면 아래와 같이 spark가 실행됩니다.
- 저는 아나콘다를 써서 spark 실행 전 주석이 길어졌습니다.
'Data_Analysis > Spark, Zeppelin' 카테고리의 다른 글
| [Spark] 구조적 API 기본 연산2 - 로우 (0) | 2020.12.26 |
|---|---|
| [Spark] 구조적 API 기본 연산1 - 컬럼 (0) | 2020.12.26 |
| [Spark] 구조적 API 개요 (0) | 2020.12.23 |
| [Spark] 아파치 스파크 들어가기 (0) | 2020.12.23 |
| [Zeppelin] Zepplelin 설치 및 실행 (0) | 2020.12.20 |




댓글