Spark 포스트는 책 「스파크 완벽 가이드 : 스파크를 활용한 빅데이터 처리와 분석의 모든 것」를 바탕으로 쓴 것임을 알려드립니다.
또한, Scala 코드 위주로 작성한 점 참고 바랍니다.
스파크 완벽 가이드
스파크 창시자가 알려주는 스파크 활용과 배포, 유지 보수의 모든 것. 오픈소스 클러스터 컴퓨팅 프레임워크인 스파크의 창시자가 쓴 스파크에 대한 종합 안내서다. 스파크 사용법부터 배포, 유
www.aladin.co.kr
1. 아파치 스파크 : 빅데이터를 위한 통합 컴퓨팅 엔진과 라이브러리 집합
아파치 스파크는 "빅데이터를 위한 통합 컴퓨팅 엔진과 라이브러리 집합"이라고 설명할 수 있습니다.
여기서 통합이란 데이터 분석 작업이 다양한 처리 유형과 라이브러리를 결합하여 수행한다는 것을 뜻합니다. 스파크가 간단한 데이터 읽기 작업부터 SQL 처리, 머신러닝, 스트림 처리에 이르기까지 다양한 데이터 분석 작업을 같은 연산 엔진과 일관성 있는 API로 수행할 수 있도록 설계되어 있습니다.
또한, 스파크는 소프트웨어 영역의 여러 통합 플랫폼과 유사한 사용방식을 제공합니다. 데이터 사이언티스트는 데이터 모델링에 Python, R 등에서 제공하는 다양한 통합 라이브러리를 활용할 수 있습니다. 웹 개발자는 Node.js, Django와 같은 통합 프레임워크가 제공하는 기능을 사용할 수 있습니다. 이렇게 스파크는 통합 엔진을 제공하는 병렬 데이터 처리용 오픈 소스로서 빠르게 빅데이터 분석 업무의 표준으로 자리 잡았습니다.
2. 스파크 구조 Overview
1) 스파크 기본 아키텍처
스파크는 여러 컴퓨터의 자원을 모아 컴퓨터 클러스터의 작업 조율 역할을 합니다. 스파크가 연산에 사용할 클러스터는 스파크 Standalone 클러스터 매니저, 하둡 YARN, Meseos 같은 클러스터 매니저에서 관리합니다. 사용자는 클러스터 매니저에 스파크 애플리케이션을 제출하고, 클러스터 매니저는 애플리케이션 실행에 필요한 자원을 할당하며, 다시 사용자는 그 자원으로 작업을 처리합니다.
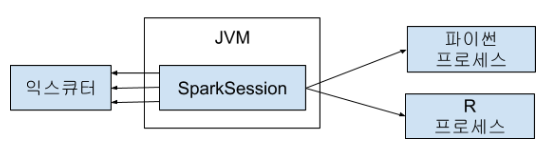
스파크 애플리케이션은 (1) 드라이버 프로세스와 (2) 익스큐터 프로세서로 구성됩니다.
(1) 드라이버 : 클러스터 노드 중 하나에서 실행되며, main() 함수를 실행합니다.
스파크 애플리케이션 정보의 유지 관리, 입력에 대한 질의 응답, 익스큐터 작업과 관련된 분석, 배포, 스케줄링 등의 작업을 담당합니다.
(2) 익스큐터 : 드라이버가 할당한 코드를 실행하고, 진행상황을 다시 보고합니다.

2) 언어 API
스파크에서는 아래 언어로 코드를 실행할 수 있습니다.
- Scala : 스파크의 기본 언어
- Java
- Python : Python은 Scala가 지원하는 거의 모든 구조를 지원합니다.
- R : 스파크에는 SparkR, sparklyr 2개 라이브러리가 있습니다.
- SQL
스파크는 위의 언어로 작성한 코드를 익스큐터의 JVM에서 실행할 수 있는 코드로 변환합니다. 이때 스파크 코드를 실행하기 위해 SparkSession 객체를 진입점으로 사용할 수 있습니다.
3. 스파크 시작하기
1) SparkSession
애플리케이션은 SparkSession 드라이버 프로세스로 제어합니다. 1개의 SparkSession은 1개의 스파크 애플리케이션에 대응합니다.
// 아래 코드 실행하여 SparkSession을 확인
spark
2) DataFrame
DataFrame은 대표적인 구조적 API로, 테이블의 데이터를 로우와 컬럼으로 표현합니다. DataFrame은 종종 데이터가 너무 많아서 여러 대의 컴퓨터에 분산 저장하기도 합니다.
// 간단한 DataFrame
val tempDataFrame=spark.range(1000).toDF("number")
3) 트랜스포메이션
스파크의 핵심 데이터 구조는 불변성을 가집니다. 데이터프레임 구조를 변경하려면 트랜스포메이션을 사용하여 변경할 수 있습니다.
트랜스포메이션을 해도 실행 계획만 생성될 뿐, 액션을 수행하기 전까지는 원래 데이터에 아무런 변화도 일어나지 않습니다.
이를 지연연산이라고 합니다.
4) 액션
스파크는 실제 연산 수행을 위해 액션 명령을 내려야 결과를 반환합니다.
'Data_Analysis > Spark, Zeppelin' 카테고리의 다른 글
| [Spark] 구조적 API 기본 연산2 - 로우 (0) | 2020.12.26 |
|---|---|
| [Spark] 구조적 API 기본 연산1 - 컬럼 (0) | 2020.12.26 |
| [Spark] 구조적 API 개요 (0) | 2020.12.23 |
| [Zeppelin] Zepplelin 설치 및 실행 (0) | 2020.12.20 |
| [Spark] Window 10에 Spark설치 (0) | 2020.12.18 |




댓글